From DB-BERT to DB-BART and Beyond
When everything else fails, read the instructions. Let’s equip database tuning systems with the ability to read the manuals and use the gained information to enhance the knob tuning process.
 GPTuner
GPTunerBrief Introduction to Database Knob Tuning
Modern database management systems (DBMS) expose hundreds of configurable parameters (i.e., knobs) to control system behaviors. Selecting appropriate values for these knobs is crucial to improve DBMS performance (e.g., set knob ‘shared_buffers’ from PostgreSQL to 25% of the RAM to improve performance).
As a common practice, experienced Database Administrators (DBAs) take great efforts (e.g., weeks or even months) to tune the target DBMS for a given workload (i.e., a workload is a set of SQL statements).
However, manual tuning struggles to handle different workloads, hardware environments, especially in nowadays cloud environments. Thus Machine Learning (ML)-based tuning systems are proposed to search for well-performing knob configurations automatically. They can be classified into two main categories: Bayesian Optimization (BO)-based and Reinforcement Learning (RL)-based. The algorithm details are omitted here, please refer to OtterTune and CDBTune for more details, which are the representative works for BO-based and RL-based methods, respectively.
The Limitations of ML-based Tuning Systems
While ML-based DBMS tuning methods do possess the potential to eventually reach well-performing knob configurations, they often come at the cost of being resource-intensive and requiring a considerable number of iterations to achieve convergence (i.e., each iteration requires the stress-test for target workload on DBMS). Such high costs come from the complexity of the tuning problem: the configuration space is high-dimensional (e.g., PostgreSQL v14.7 has 351 knobs) and heterogeneous (e.g., a knob can be continual or categorical), and optimization algorithms struggle with this complexity. Instead of searching the configuration space only based on runtime feedback (i.e., black-box optimization), we can enhance the tuning process with domain knowledge because DBMS itself is domain-specific and there is extensive domain knowledge available from DBMS official documents, manuals, web forums. However, since such domain knowledge is expressed in natural language and seems exclusive to DBAs, the natural question is how to make the knowledge understandable to machines and use the gained information to enhance the knob tuning process?
DB-BERT: a Database Tuning Tool that “Reads the Manual”
DB-BERT is an excellent work that utilizes a pre-trained language model (BERT) to mine tuning hints from manuals and use the hints to guide the iterative optimization process (Specifically, the process is based on Double Deep Q-Networks, a Reinforcement Learning algorithm).
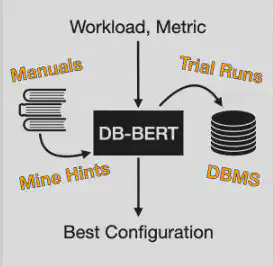
An Simple Example of Extracting Tuning Hints from Manuals
Given the following text snippet from PostgreSQL official document:
a reasonable starting value for knob ‘shared_buffers’ is 25% of the memory in your system
The extracted tuning hint should be:
shared_buffers = 0.25 * RAM
How does DB-BERT work?
DB-BERT models the tuning process as three “Multiple Choice Question Answering” problems and utilize Reinforcement Learning to fine-tune a BERT model to answer the three problems. The three questions and the according choices are as follows:
- Q1: What is the relationship between the knob and the hardware?
- answer 0: {param} and {value} relate to main memory
- answer 1: {param} and {value} relate to hard disk
- answer 2: {param} and {value} relate to core counts
- answer 3: Set {param} to {value}
- answer 4: {param} and {value} are unrelated
- Q2: How should I deviate the suggested value?
- answer 0: Set {param} much lower than {value}
- answer 1: Set {param} slightly below {value}
- answer 2: Set {param} to {value}
- answer 3: Set {param} slightly above {value}
- answer 4: Set {param} much higher than {value}
- Q3: How should I give weight for hints from different sources?
- answer 0: The hint on {param} is not important
- answer 1: The hint on {param} is slightly important
- answer 2: The hint on {param} is quite important
- answer 3: The hint on {param} is very important
- answer 4: The hint on {param} is extremely important
The three questions are answered for each text snippet. For the second and the third problem, we apply factors {0.25, 0.5, 1, 2, 4} and {0, 2, 4, 8, 16}, respectively.
To be clear, let’s consider the following running example:
Given:
- a text snippet “a reasonable starting value for knob ‘shared_buffers’ is 25% of the memory in your system”
- hardware properties “RAM = 16 GB, Disk = 1 TB, Core Counts = 32”
DB-BERT works in the following ways:
- we at first extract the knob name and knob value from it: {shared_buffers, 0.25}.
- assume BERT answers Q1 with answer ‘0’, we get the expression:
- shared_buffers = 0.25 * 16 GB
- assume BERT answers Q2 with answer ‘3’, we get the expression:
- shared_buffers = 0.25 * 16 GB * 2
- assume BERT answers Q3 with answer ‘4’, and another text “set shared_buffers to 0” gets the answer ‘0’, since 16 is larger than 0, snippet “set to 25% of the memory” will be considered with higher priority
In summary, DB-BERT relates a knob to its hardware context (i.e., RAM, Disk or CPU Cores), creates a discrete space based on the suggested value mentioned in the manuals (i.e., {0.25 * d, 0.5 * d, d, 2 * d, 4 * d}, where d is the suggested value), and takes hints from different resources into consideration (i.e., apply weight for each hint as priority).
In pratice, DB-BERT requires offline training to fine-tune the BERT model. When the knob tuning process starts, the BERT model is still iteratively fine-tuned to give better answers based on the reward given by RL, which considers DBMS runtime feedback. For more details, please refer to the DB-BERT paper.
From DB-BERT to DB-BART and DB-GPT-4
Since fine-tuning requires training data preparation and hardware resources, DB-BERT then uses BART as its language model (despite the project name) to leverage its zero-shot classification ability, and thus no longer requires training. Except for the different language model used, DB-BART (for the purpose of distinguishing) works in a different way compared to that of DB-BERT and I summarize it in the following figure:

Instead of using language model to answer the questions directly, DB-BART treats the language model as “an encoder” to provide “observation” for RL neural networks, and the questions are answered by RL. Specifically, the observation vector is defined as follows:
[ doc_id, hint_id, Q_id, S(0), S(1), S(2), S(3), S(4) ]
where doc_id, hint_id and Q_id identify the hint source, which hint and which question, respectively. S(i) is the score BART gives for each choice, ranging from 0 to 1 with a bigger value indicating that it is more likely to be the correct answer.
Since GPT-4 serves as a more powerful large language model, we extend DB-BART to DB-GPT-4 by using GPT-4 to score for each choice. Unfortunately, there is no performance improvement. We think this is because DB-BERT series do not have high demand on the quality of language models and its design cannot leverage the amazing capability of GPT-4 (After all, powerful language models like GPT-4 had not yet been developed at that time). Thus the next problem is how to utilize the modern large language model to enhance the knob tuning process?
Beyond DB-BERT Series: GPTuner
In practice, DB-BERT series converge faster than traditional ML-based tuning approaches since it benefits from the information gained from text analysis. However, it only lead to sub-optimal performance for two main reasons. Firstly, it leverages the domain knowledge in a limited way (i.e., it only take suggested value into consideration). Secondly, its exploration of the configuration space is inadequate (i.e., it only explore a limited discrete space).
Facing the two limitations, we develop a novel approach:
GPTuner: A Manual-Reading Database Tuning System via GPT-Guided Bayesian Optimization
GPTuner takes more information into consideration (e.g., we discard meaningless regions, highlight promising space and handle special situations), and explores the optimized space with a novel Coarse-to-Fine Bayesian Optimization Framework (e.g., we aim to achieve the efficiency of Coarse-grained Search and the delicacy of Fine-grained Search). Specifically, GPTuner employs a LLM-based pipeline to extract and handle multi-source knowledge, a prompt ensemble algorithm to transfer the semi-structured knowledge into a structured view, a series of knowledge-based optimizations to optimize the configuration space from two aspects, and a Coarse-to-Fine Bayesian Optimization Framework to explore the optimized space.
We present the system overview of GPTuner below. For more details, please refer to the GPTuner Project.
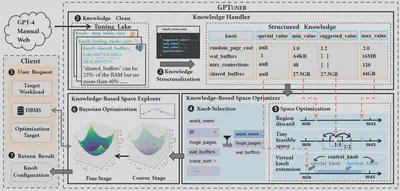
Comparison between DB-BERT Series and GPTuner
The main differences between DB-BERT Series and GPTuner
| Criterion | DB-BERT | GPTuner |
|---|---|---|
| Language Model | BERT / BART / GPT-4 | GPT-4 |
| Workload Aware | no | yes |
| Require Fine-Tuning | yes / no / no | no |
| Filter Illegal | no | yes |
| Space Type | Discrete Space | Heterogeneous Space |
| Optimization Algorithm | Reinforcement Learning | Coarse-to-Fine Bayesian Optimization |
| Considered Guidance | Suggested Value | Suggested Value Bound Constraint Special Cases |
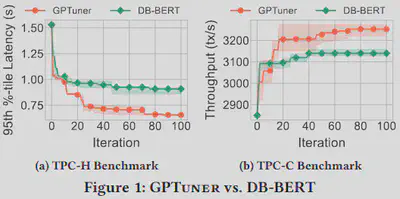
Performance Comparison
Jiale Lao
Graduate Student
My research interests include database, machine learning and large language model.